Adjunct Research Assistant Professor with University of Southern California (USC), Los Angeles till August 2022
Worked as Research Scientist on big DARPA projects (Dept. of Defense) of USA.
| Topic | Authors | Book | Difficulty |
|---|---|---|---|
| Generic ML | H. Daumé III | "A Course in Machine Learning", download the book | Easy |
| Generic ML | Christopher M. Bishop | “Pattern Recognition and Machine Learning” download the book | Difficult |
There is not a single textbook but suggested are:
| Topic | Authors | Book |
|---|---|---|
| Generic ML | H. Daumé III | "A Course in Machine Learning", download the book |
| Generic ML | Christopher M. Bishop | “Pattern Recognition and Machine Learning” download the book |
| Generic ML | Kevin P. Murphy | “Probabilistic Machine Learning: An introduction", MIT Press, 2021 |
| Deep Learning | Ian Goodfellow and Yoshua Bengio and Aaron Courville | “Deep Learning”, MIT Press 2016 |
| Deep Learning | Ston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola | “Dive into Deep Learning” |
| Deep Learning | Simone Scardapane (uniroma1!) | Alice's Adventures in a Differentiable Wonderland |
You can find online most of these or part of them.
Authors keep the PDF freely available Check the license if you can print it though!


Credits: This program and material was inspired by the following courses:
AND(round(Unit1) >= 15,round(Unit2) >= 15,
round(Unit1+Unit2 grade) >= 32)
round means 0.3 is 0 and 0.9 is 1 (the threshold is at 0.5)
So for example if you attain 14.5 at Unit 1, you have to score 17/17 to Unit 2 hence you get 14.5+17 = 31.5 --> round(31.5)=32
Note: a Unit is passed if score >= 8.5 (18/30)
No mandatory requirements but math tools that come in handy
You may be covering this in AI Lab class so I will not go much in details.
| Topic | Hours |
|---|---|
| Intro to ML, Correlation and Learning Paradigms | 6 |
| Linear Algebra Foundations | |
| Geometry of Linear Maps, Numpy Tensors, PCA | 9 |
| Dimensionality Reduction & Generative Models | |
| PCA, SVD, Linear Generative Modeling, 3DMM | 9 |
| Probabilistic Modeling & Regression | |
| MLE, Gaussian Mixture Models, Linear Regression | 15 |
| 📝 Self-Assessment (1st part) 🤓 | 3 |
| Easter Vacation | |
| 📝 Mid-Term (post vacation) | 3 |
| Regularization & Optimization | |
| L2 Regularization, Logistic Regression, Gradient Descent | 9 |
| Neural Networks & AutoDiff | |
| MLP, AutoDiff (PyTorch/JAX), Signed Distance Functions | 9 |
| Implicit Representations & Diffusion Models | |
| NeRFs, Flow, Score Matching, Diffusion | 6 |
| Exam Preparation and Final | |
| Ask Me Anything + 📝 Final-Term | 6 |
| Total | 66 |
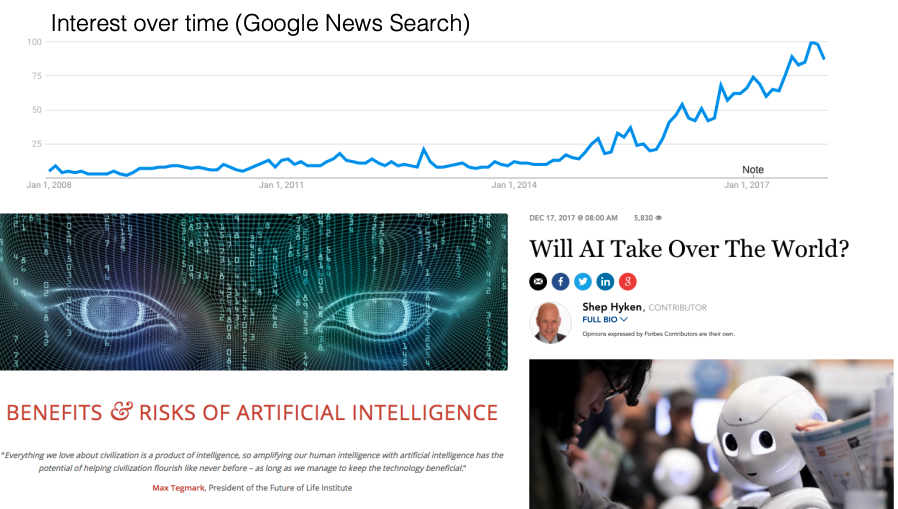
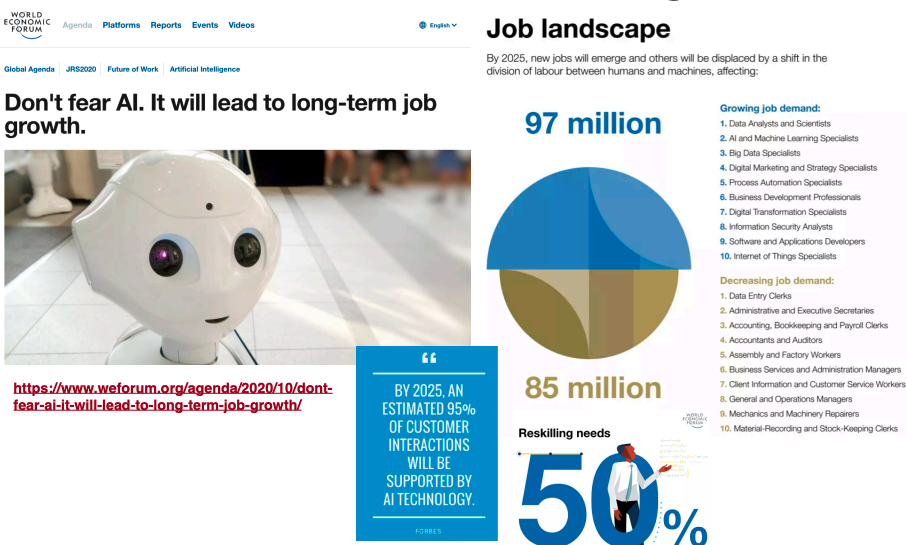
An AI&ML student from previous year, given that they studied hard AI&ML (along with Unit I and AI Lab), was able to secure an internship with Hewlett-Packard Enterprise (HPE). The student told me that:



The imitation game (based on language):
The interrogator tries to determine which player is a computer and which is a human

J. McCarthy, who coined the term in 1956, defines AI as
the science and engineering of making intelligent machines
A modern definition of AI:
"The ability of a digital computer or computer-controlled robot to perform tasks commonly associated with intelligent beings"
First definition in 1959 by Arthur Lee Samuel:
ML is the field of study that gives computers the ability to learn without being explicitly programmed.
ML is the study of computer algorithms that improve automatically through experience.
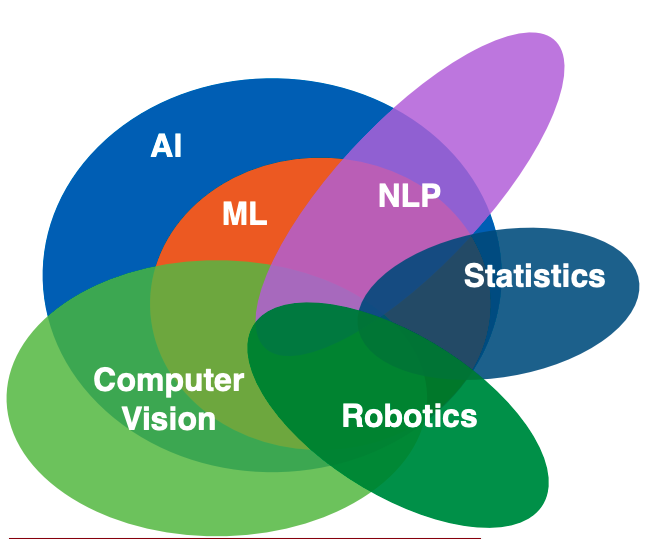
vision = let machine see the worldThere are two types of problems.
1) Problems solvable using algorithms developed by humans with a set of rules:
As computer scientists (or mathematicians) we design an algorithm and write a program that encodes a set of rules that is useful to solve the problem
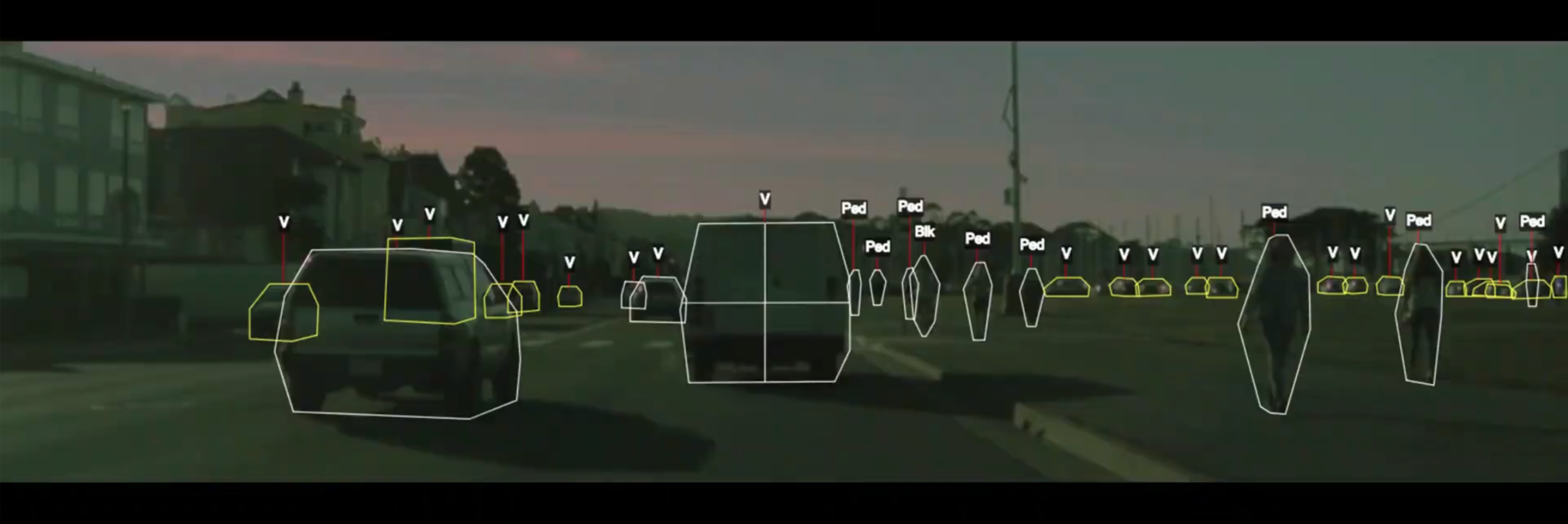
A self-driving car system uses dozens of components that include detection of cars, pedestrians, and other objects.

Credits Cornell CS5785
One way to build a detection system is to write down rules.

Credits Cornell CS5785
object = camera.get_object()
if object.has_wheels(): # does the object have wheels?
if len(object.wheels) == 4: return "Car" # four wheels => car
elif len(object.wheels) == 2:,
if object.seen_from_back():
return "Car" # viewed from back, car has 2 wheels
else:
return "Bicycle" # normally, 2 wheels => bicycle
return "Unknown" # no wheels? we don't know what it is
Credits Cornell CS5785
In practice, it's almost impossible for a human to specify all the edge cases.
The machine learning approach is to teach a computer how to do detection by showing it many examples of different objects.
No manual programming is needed: the computer learns what defines a pedestrian or a car on its own!
Credits Cornell CS5785
2) Problems that are very hard to solve with a set of rules
As ML engineer/data scientist/research scientist we design and optimize a model that learns patterns and extract "rules" from data that are useful to solve the problem
Big difference is: instead of writing the algorithm, we write the optimization for the hypothesis.
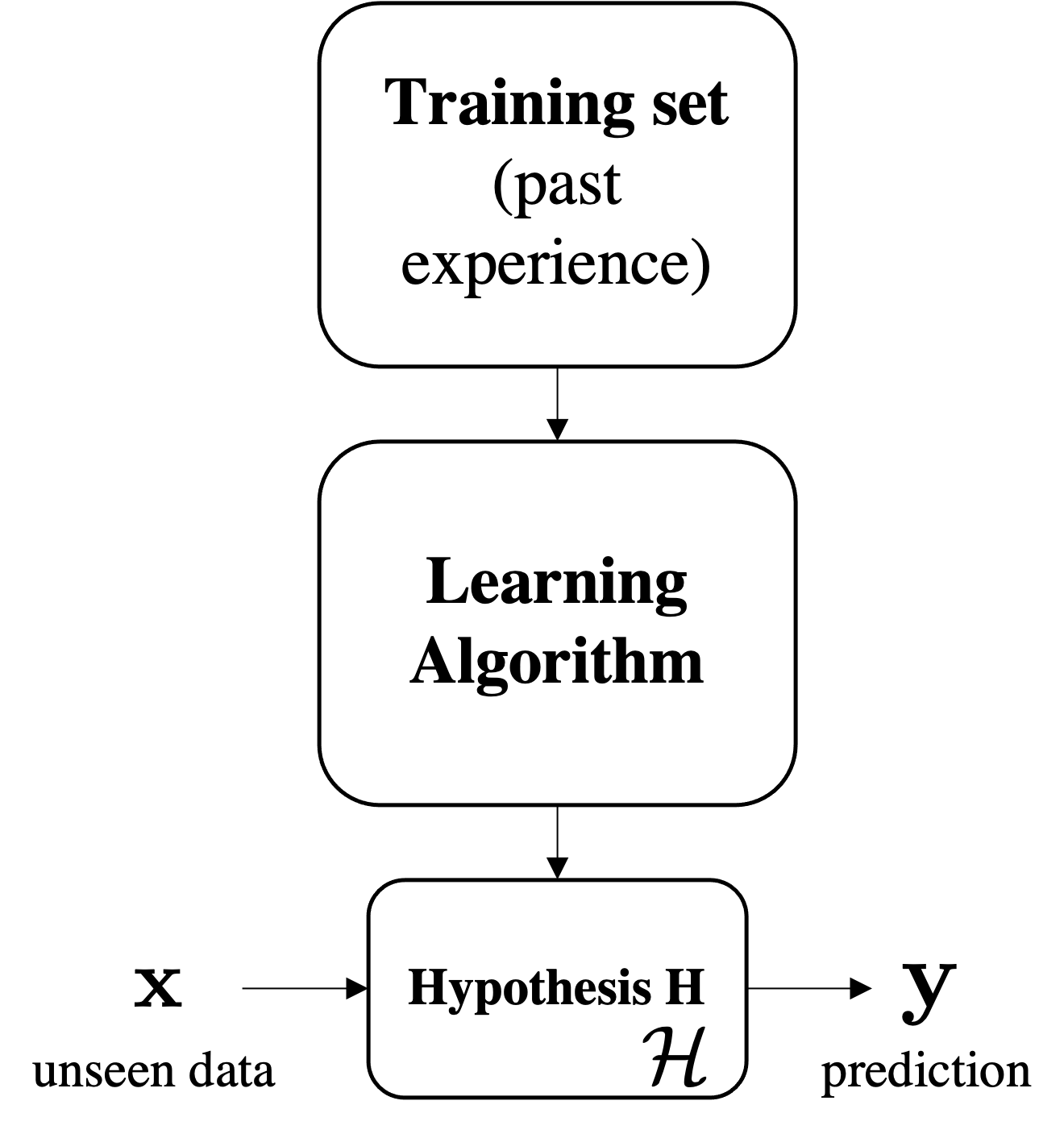
To apply supervised learning, we define a dataset and a learning algorithm.
$$ \underbrace{\text{Dataset}}_\text{Features, Attributes, Targets} + \underbrace{\text{Learning Algorithm}}_\text{Model Class + Objective + Optimizer } \to \text{Predictive Model} $$The output is a predictive model that maps inputs to targets. For instance, it can predict targets on new inputs.
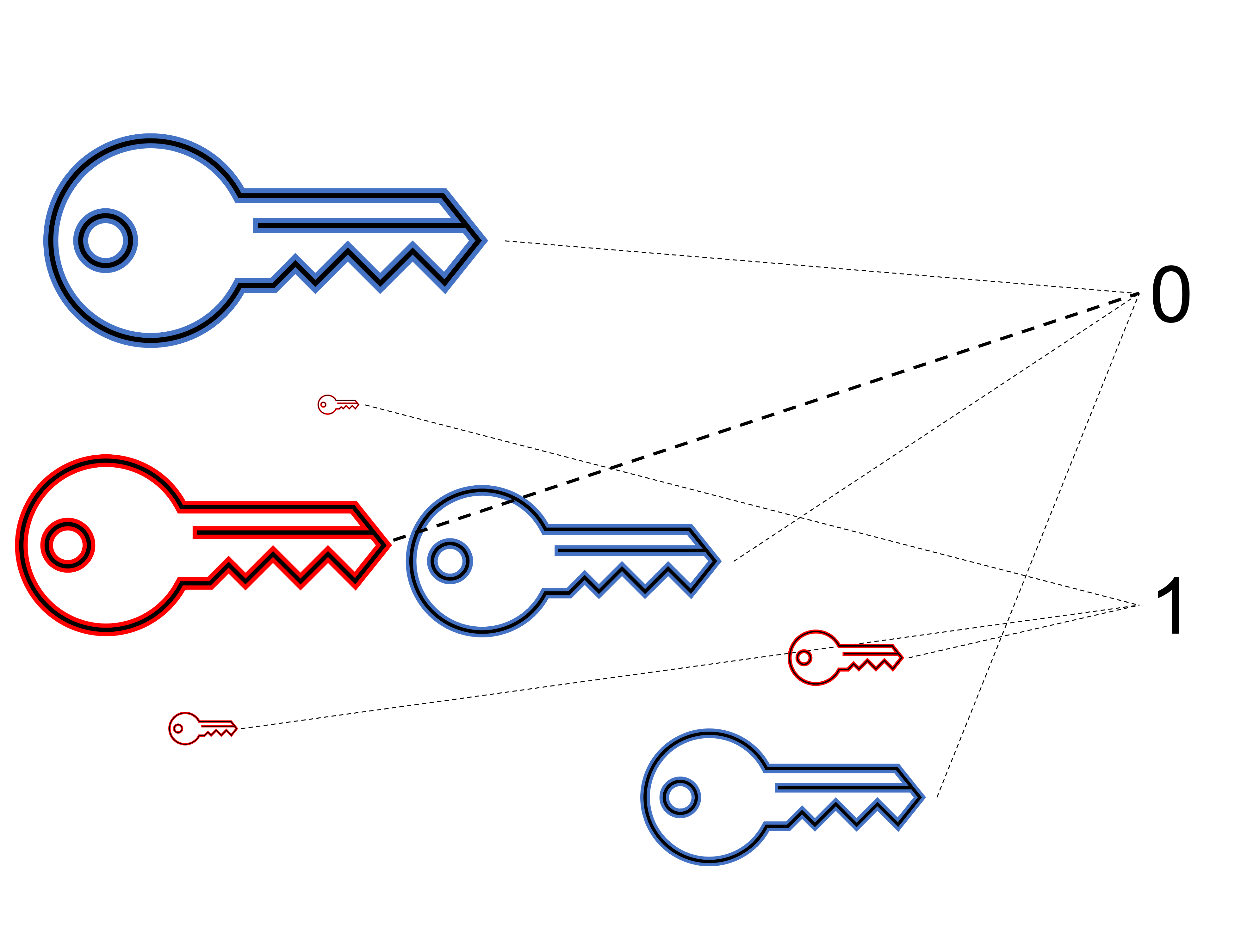
Store predefined templates of faces as images with those closed set identities. Take all the pixel at position (x,y) and if then else then...Learn a function that maps input images to an identity using prior data. We will soon see that learning $\approx$ optimizing.



You probably use ML dozens of times a day without even knowing it:
[Information Retrieval] A web search on Google works well because a software based on ML has figured out how to rank pages
[Spam Filter/Classifier] Each time you check your e-mail a spam filter has learned how to distinguish spam from not-spam e-mails
[Face Recognition] When Facebook or Apple's photo application recognizes your friends in your pictures, that's also because of ML ## and useful in many tasks
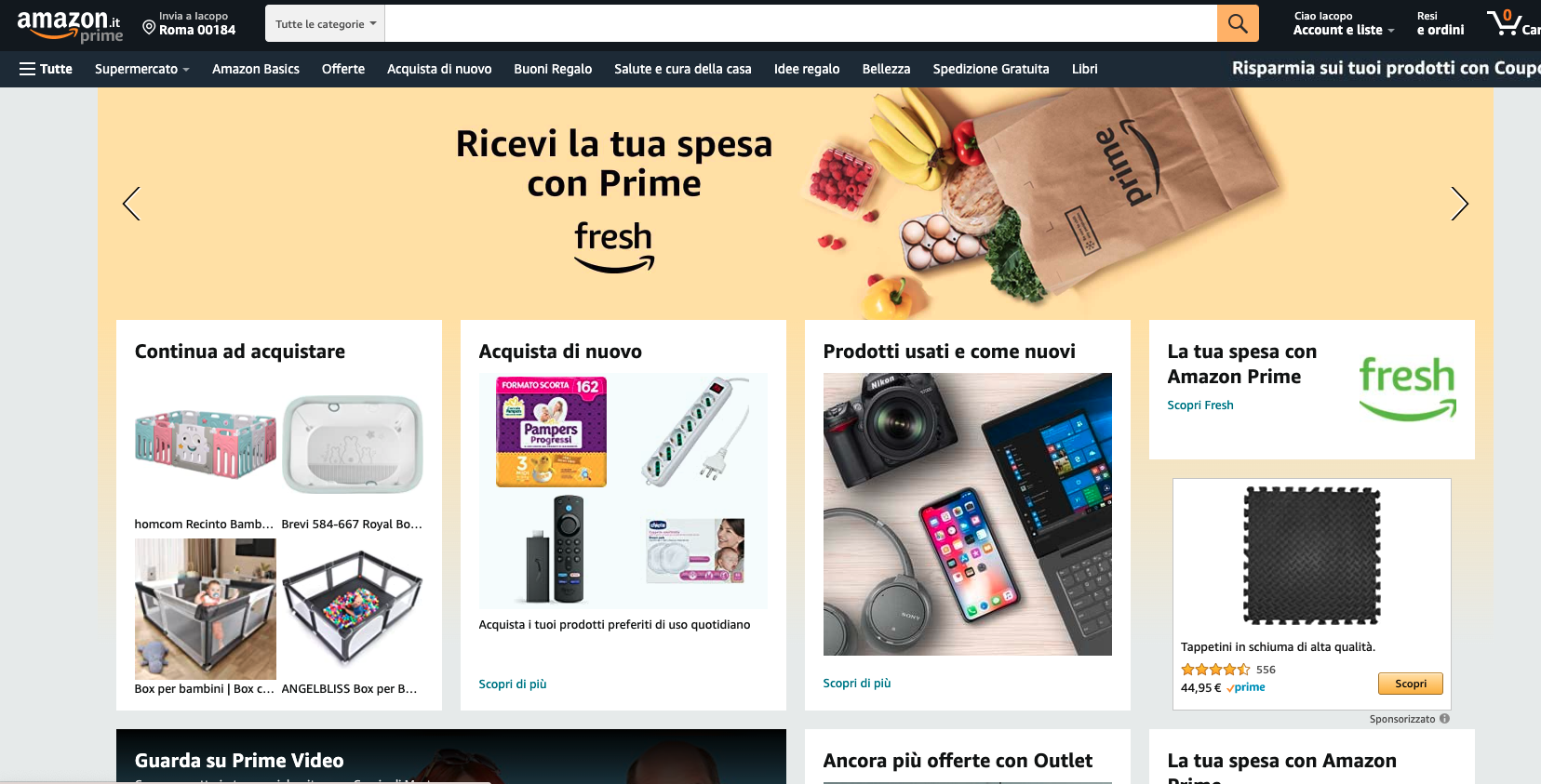


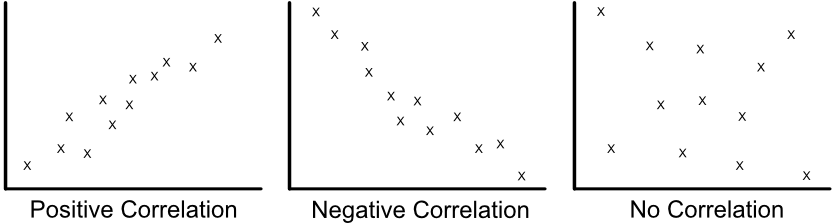
Graphics from [this link](https://wtmaths.com/correlation.html)

| X1 | X2 |
|---|---|
| 0.1 | 45 |
| 0.1 | 65 |
| 0.2 | 28 |
| 0.3 | 76 |
| 0.5 | 55 |
| 0.6 | 48 |
| 0.9 | 64 |
| 1.1 | 41 |
| 1.5 | 30 |
| 1.8 | 52 |
| 1.8 | 75 |
| 1.9 | 35 |
| 2.1 | 42 |
| 2.2 | 65 |
| 3.0 | 30 |
| 3.6 | 71 |
$ \rho_{X,Y}= \frac{\operatorname{cov}(X,Y)}{\sigma_X \sigma_Y}$
where:
The formula for $\rho$ can be expressed in terms of mean and expectation.
$$\operatorname{cov}(X,Y) = \mathbb{E}[(X-\mu_X)(Y-\mu_Y)]$$So Pearson correlation $\rho$ can also be written as:
$$\rho_{X,Y}=\frac{\mathbb{E}[(X-\mu_X)(Y-\mu_Y)]}{\sigma_X\sigma_Y}$$[-1,+1]0 means that there is no linear dependency between variables







...but we have to be careful when predicting....



We will see what happens with ML when you have a low number of samples for training.
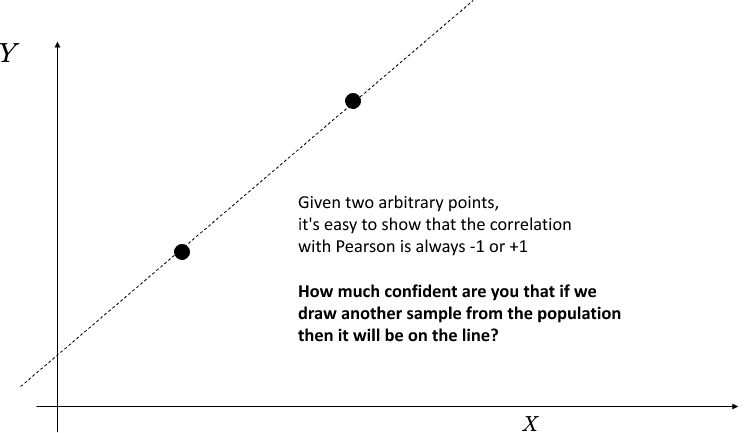


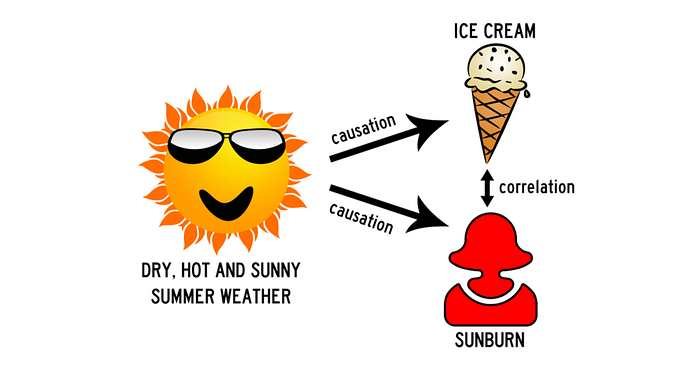
If given two variable $A$ and $B$, we see that by increasing $A$, $B$ increases as well:
Graphics from [this link](https://sundaskhalid.medium.com/correlation-vs-causation-in-data-science-66b6cfa702f0)

Graphics xcd comic
| Class A | Class B |
|---|---|
 |
 |

| parrot | squirrel | cat | penguin |
|---|---|---|---|
| A | B | B | A |
| A | A | B | B |
This preference for one distinction (bird/non-bird) over another (fly/no-fly) is a bias that different human learners have.
In the context of machine learning, it is called inductive bias: in the absense of data that narrow down the relevant concept, what type of solutions are we more likely to prefer?
Most of methods covered in this course are "Inductive"---as opposed to transductive.


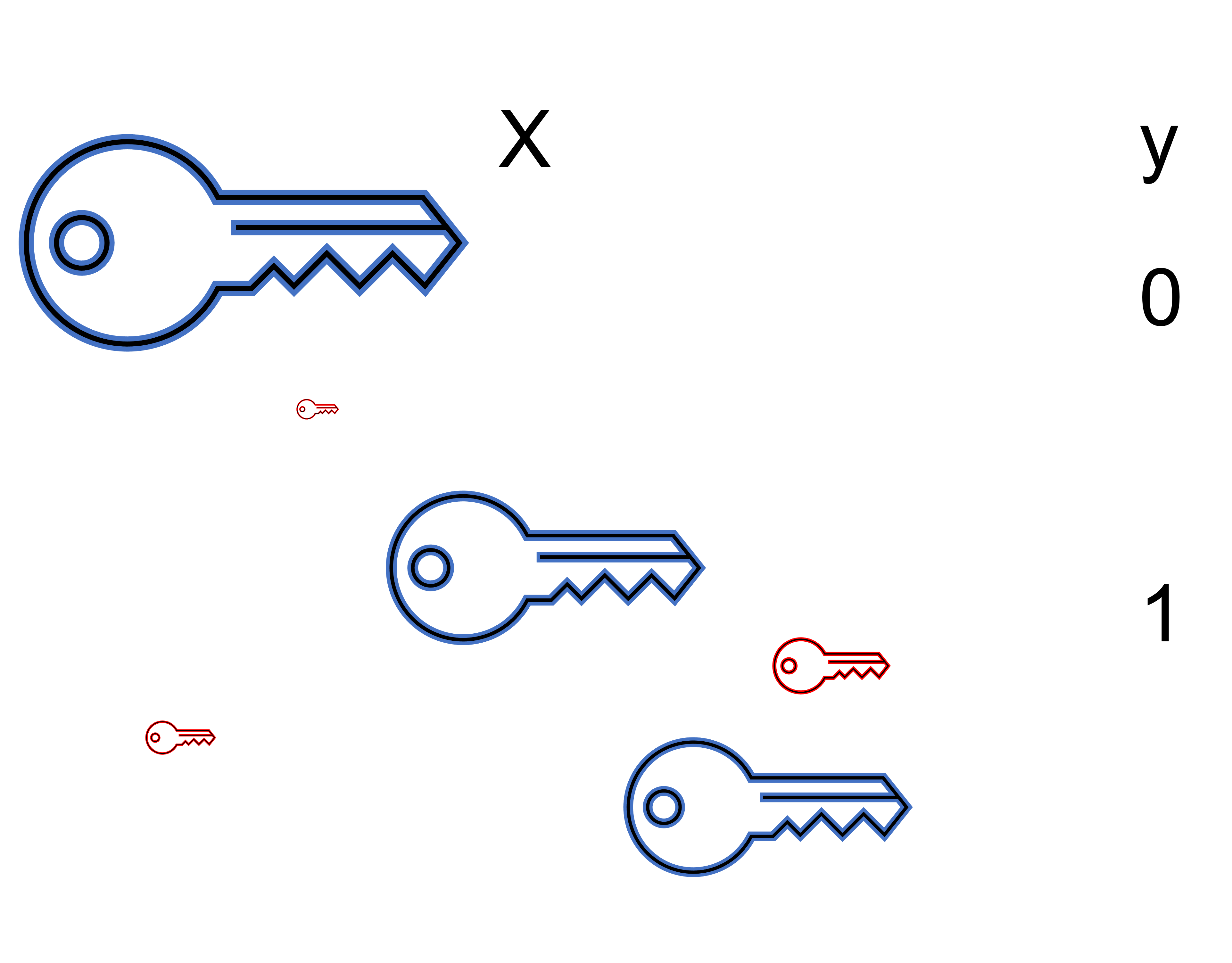
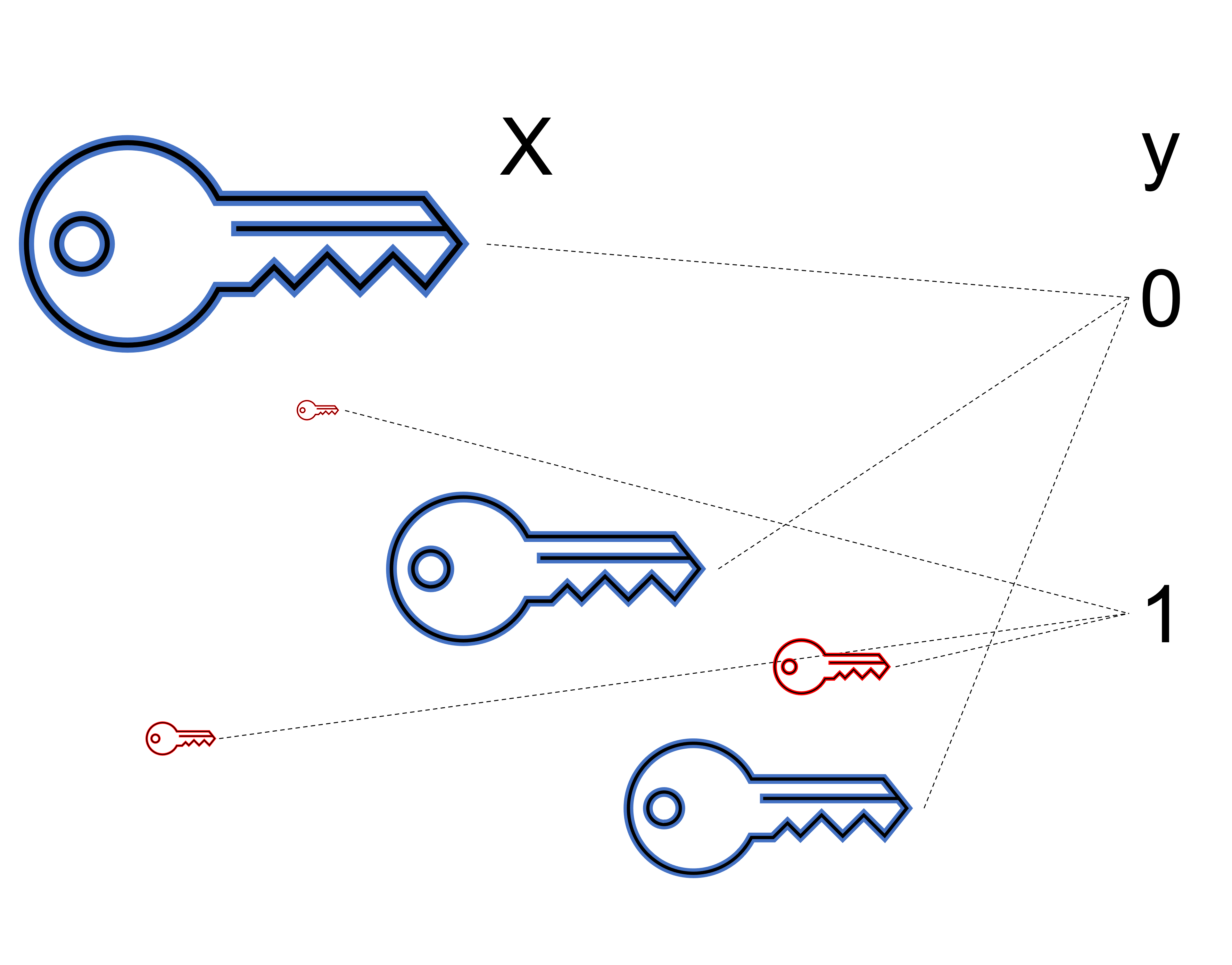
Assume that there is a unknown and complex generator $\mathcal{D}$ that provides output pairs $(\mathbf{x},y)$.
The most common approach to machine learning is supervised learning.
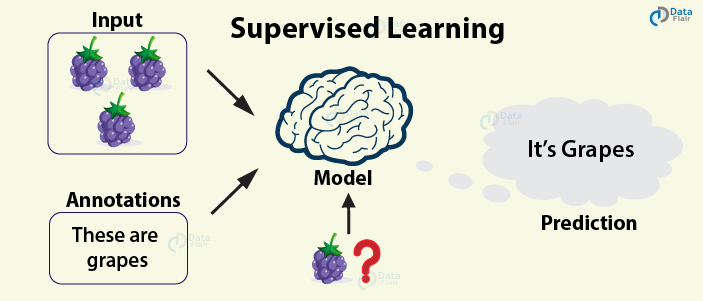
Image Credit: DataFlair
We previously saw an example of supervised learning: object detection.
Credits Cornell CS5785
Many important applications of machine learning are supervised:
In practice, in a real-world problem no one has access to $\mathcal{D}$ because problems are too complex
Try to write a computer program to generate all possible natural images that you can find in the world. Is it easy?
Let's assume here that we have access to $\mathcal{D}$ as a python function get_prob_under_D(x,y) that takes as input a pair (x,y) and returns the probability of the pair under $\mathcal{D}$.
If so, we can define the Bayes optimal classifier as the classifier that:
get_prob_under_D(x,y) The take-home message is that if someone gave you access to the "data distribution", forming an optimal classifier would be trivial.
Unfortunately, no one gave you the implementation of this distribution.
where:
Goal: given a training set with labels, learn a function over a set of possible functions (hypothesis over a Hypothesis set)
$$h \in \mathcal{H}\text{ so that }h : \mathbf{x} \mapsto y$$Output of the learning is $h(\cdot)$ that can be used to do prediction at test-time.
Prediction: Classification (discrete-valued) vs Regression (real-valued output)
From cimi book:
Do not look at your test data. Even once. Even a tiny peek. Once you do that, it is not test data any more. Yes, perhaps your algorithm hasn’t seen it. But you have. And you are likely a better learner than your learning algorithm. Consciously or otherwise, you might make decisions based on whatever you might have seen. Once you look at the test data, your model’s performance on it is no longer indicative of it’s performance on future unseen data. This is simply because future data is unseen, but your “test” data no longer is.
Here, we have a dataset without labels. Our goal is to learn something interesting about the structure of the data.
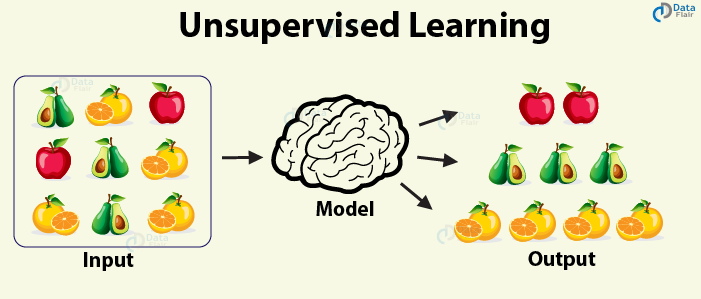
Image Credit: DataFlair

Image from [scikit-learn](https://scikit-learn.org/stable/modules/clustering.html#clustering)

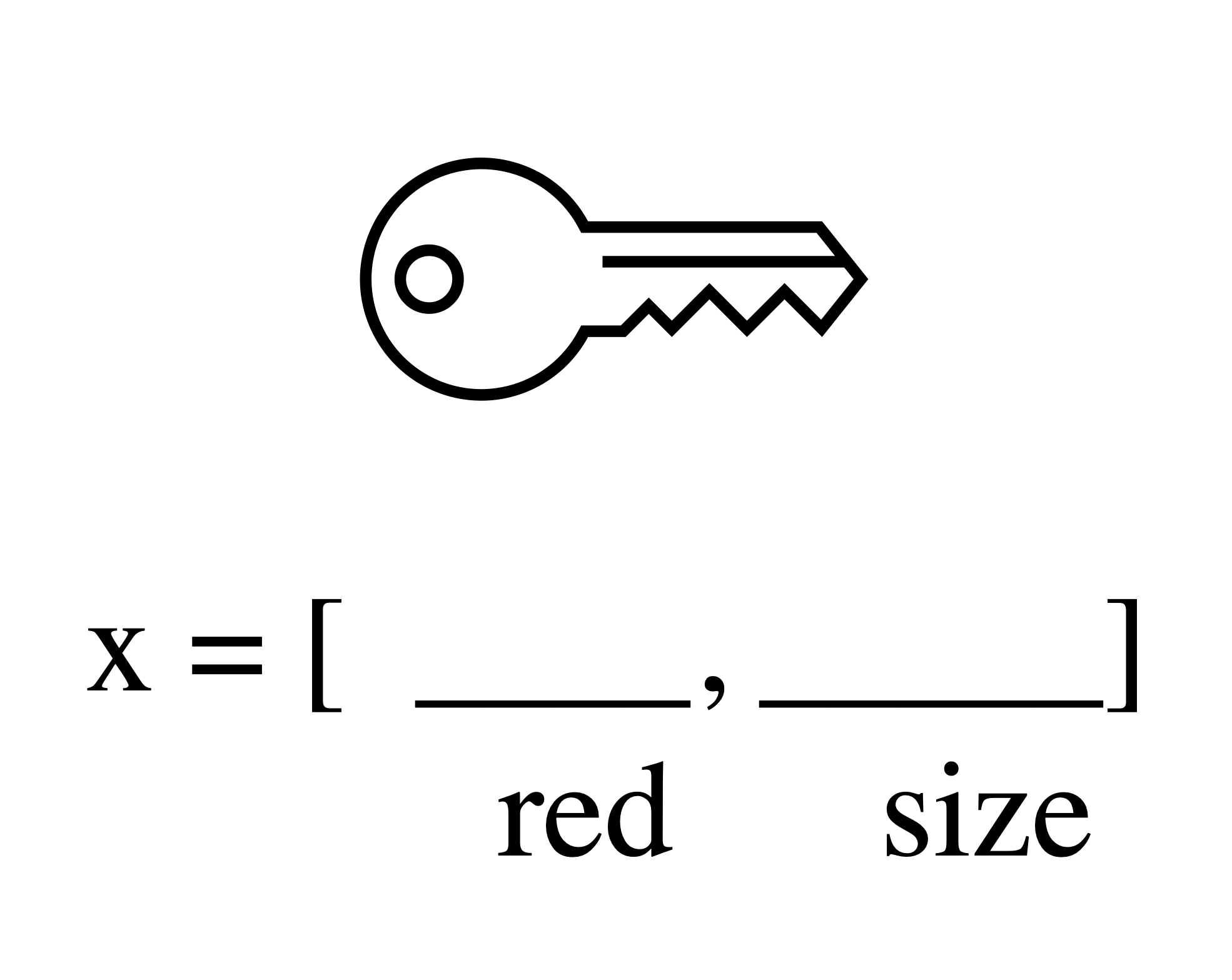



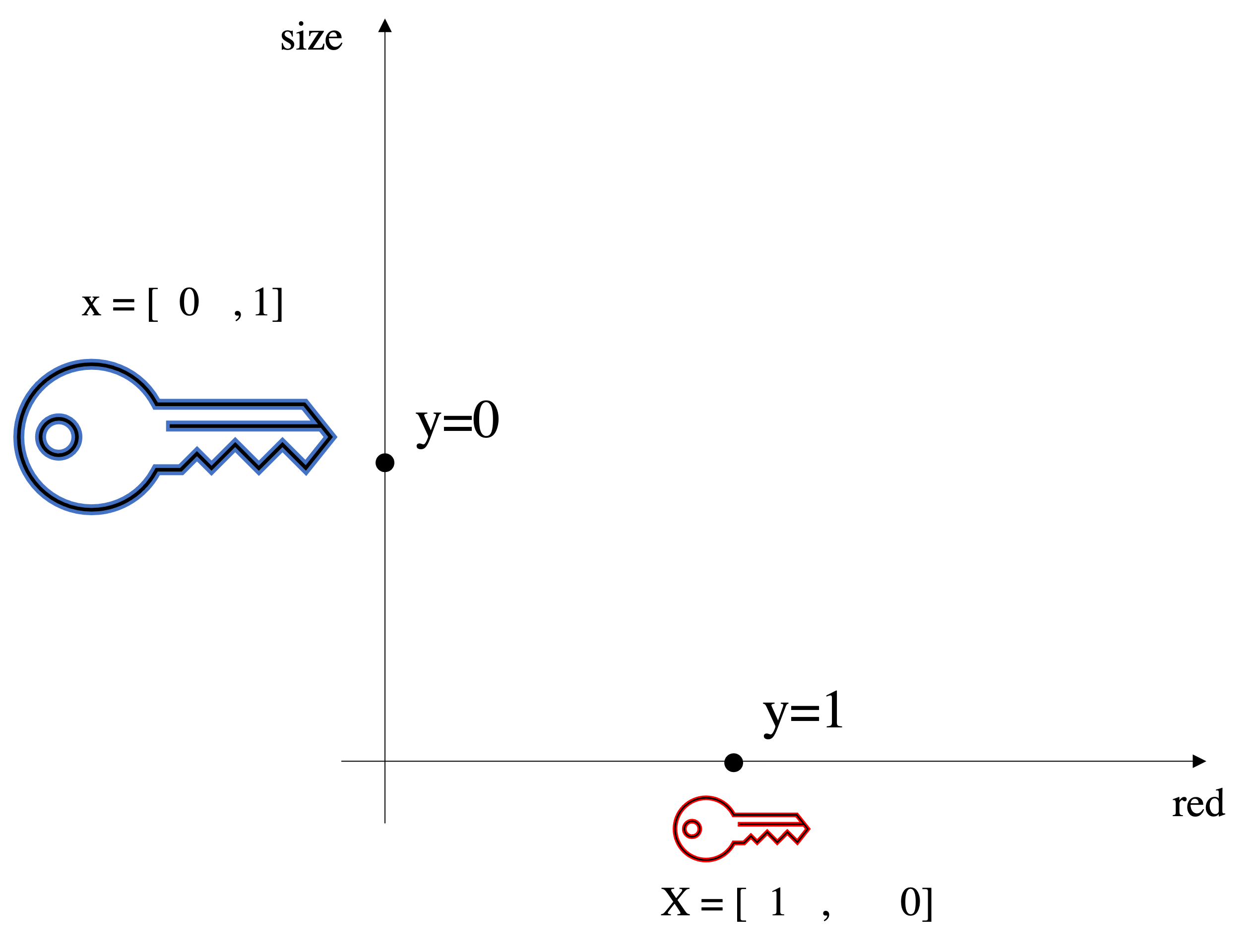
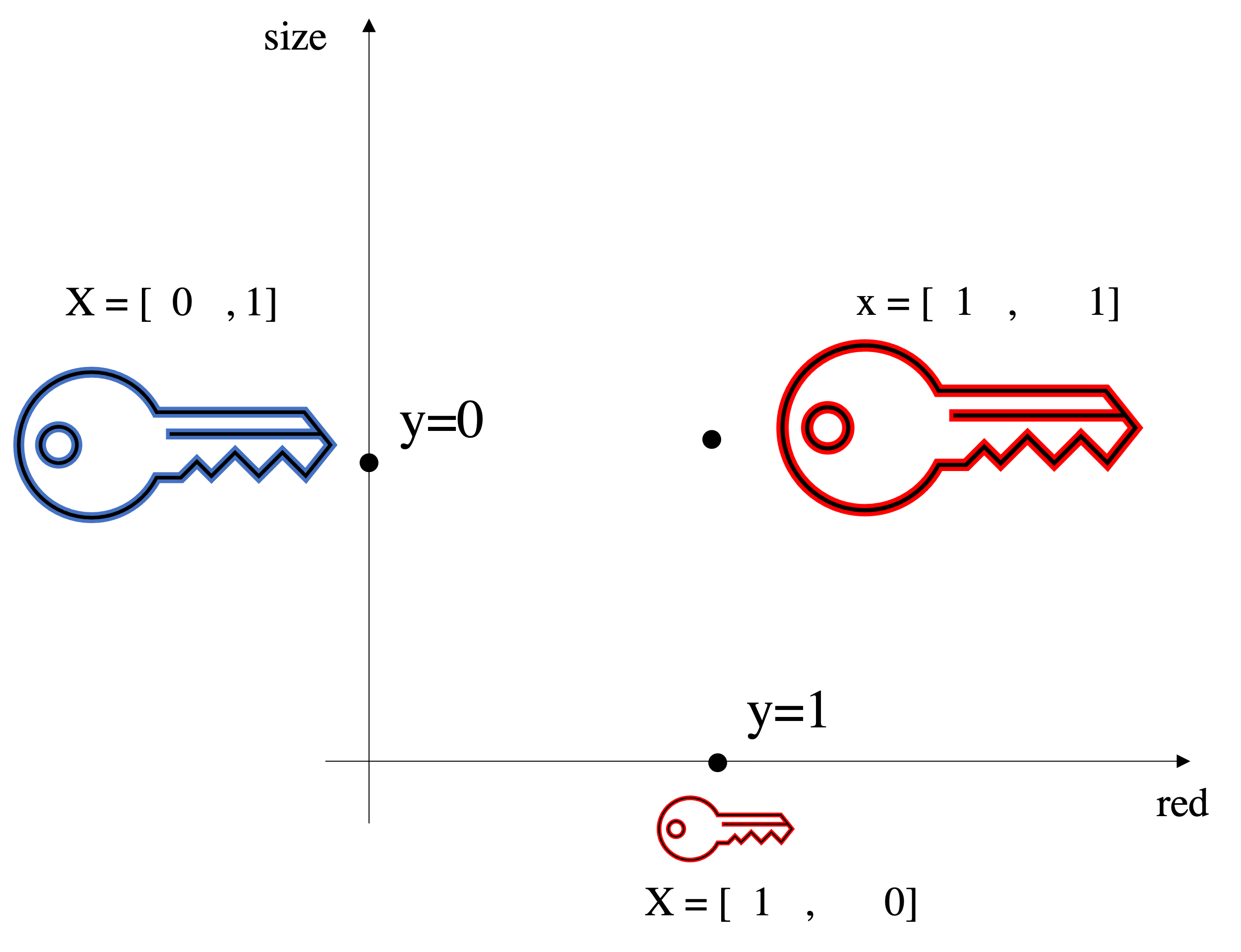
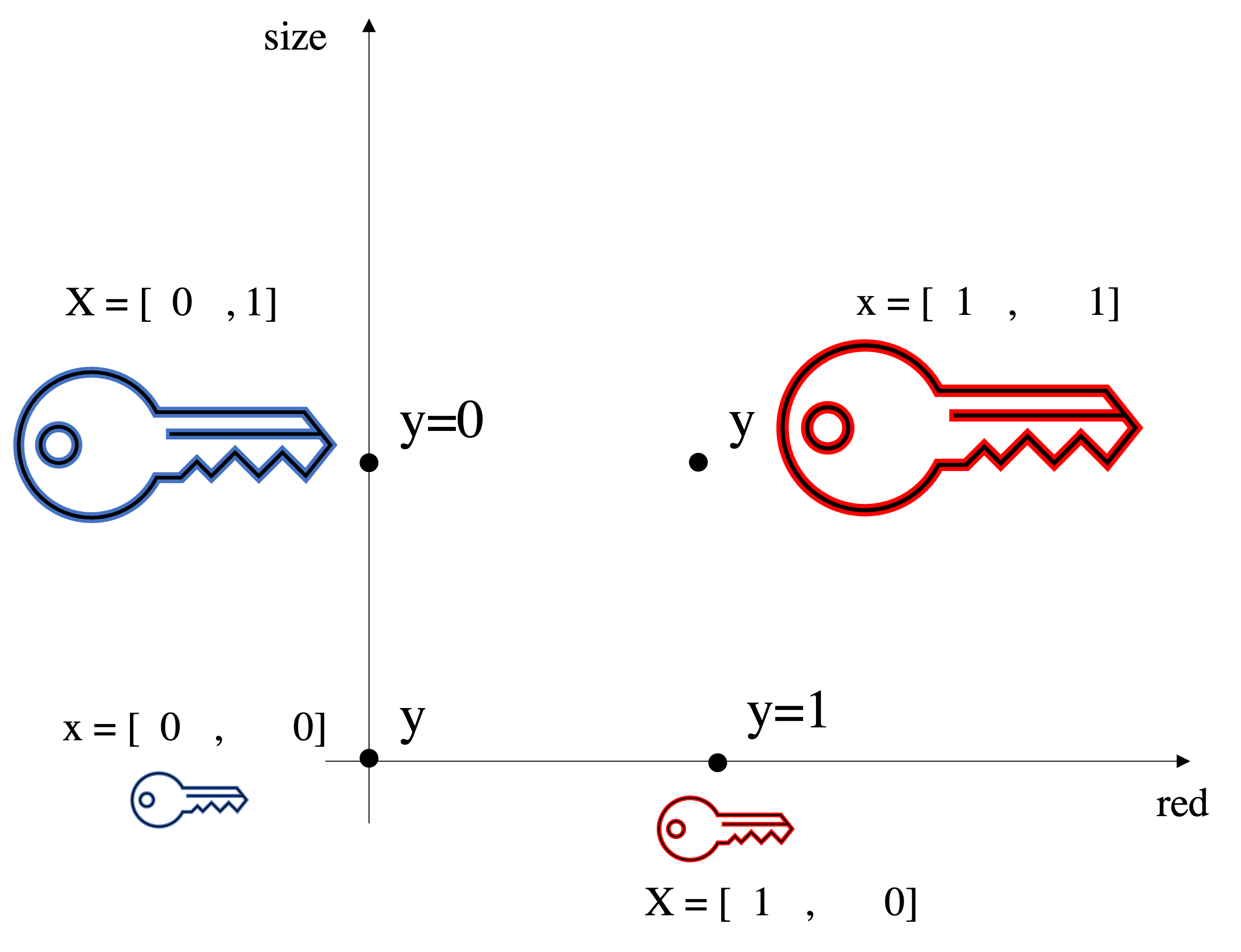
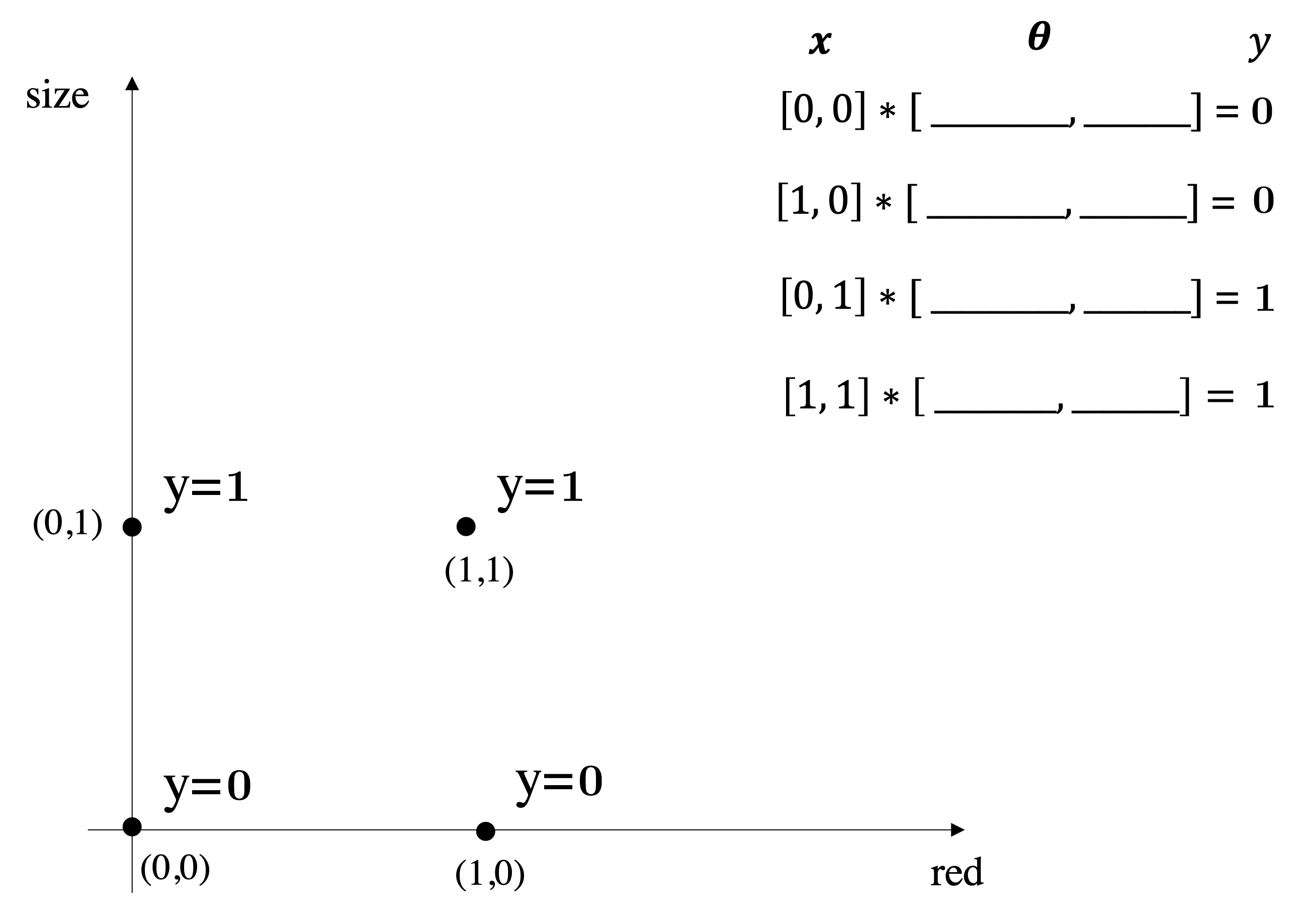

Matrix and array manipulation Numpy
![]()
Basic ML methods implemented Scikit Learn
![]()
Plotting and Visualization Tool: MatplotLib
![]()
Thank you for your attention