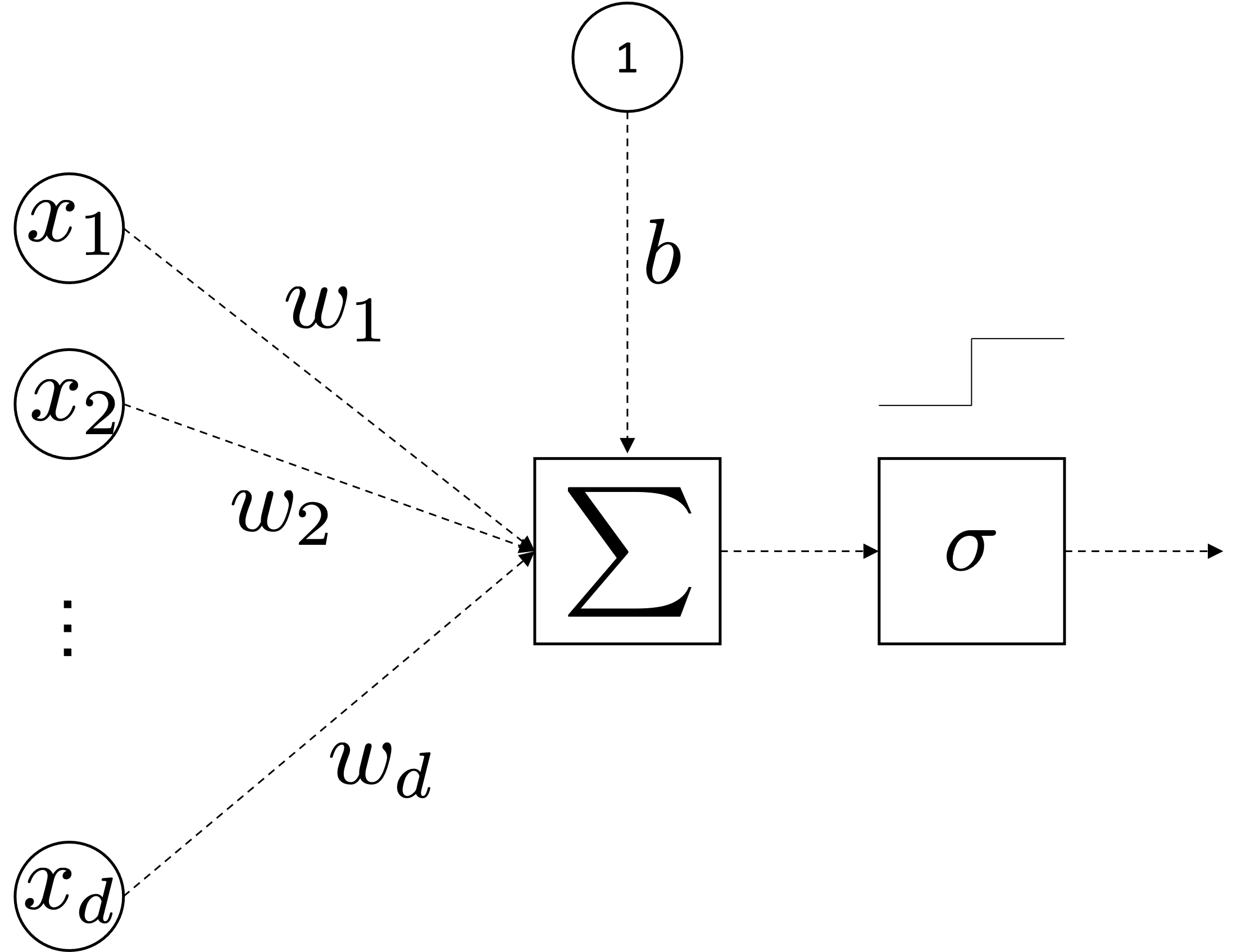
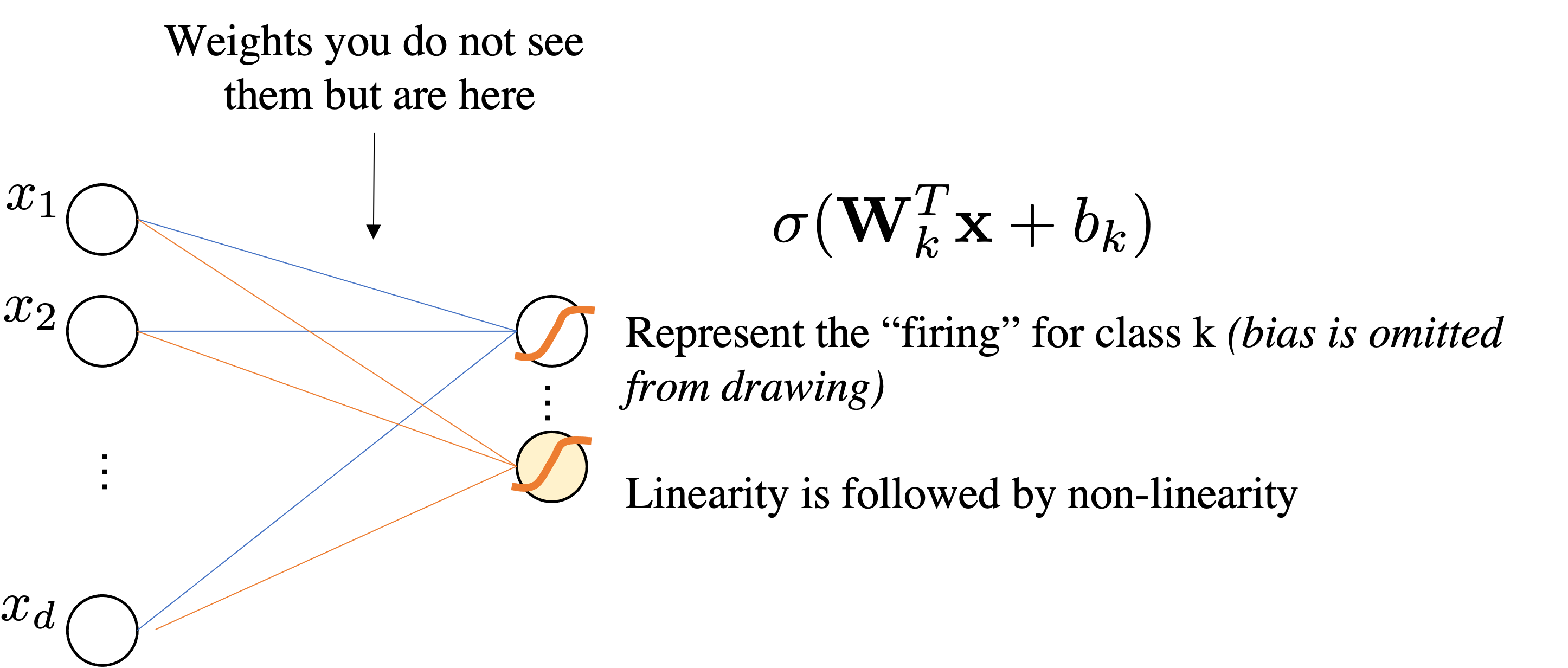
Let's consider our linear softmax regressor
$$ \underbrace{\mbf{z}}_{\mathbb{R}^{Kx1}} = \underbrace{\mbf{W}}_{\mathbb{R}^{K\times d}}\underbrace{\mbf{x}}_{\mathbb{R}^{d\times1}} + \underbrace{\mbf{b}}_{\mathbb{R}^K}$$We interpret as Linear Layer $\mathbf{W} \mathbf{x}+\bmf{b}$ followed by Non-Linear Activation function $\sigma$
$$ \sigma(\mathbf{W} \mathbf{x} + \bmf{b})=\sigma \circ\left(\begin{array}{cccc} w_{11} & w_{12} & \cdots & w_{1 d} \\ w_{21} & w_{22} & \cdots & w_{2 d} \\ \vdots & \cdots & \ddots & \vdots \\ w_{k 1} & w_{m 2} & \cdots & w_{k d} \end{array}\right)\left(\begin{array}{c} x_{1} \\ x_{2} \\ \vdots \\ x_{d} \end{array}\right)+ \left(\begin{array}{c} b_{1} \\ b_{2} \\ \vdots \\ b_{k} \end{array}\right) =\sigma \circ\left(\begin{array}{c} z_{1} \\ z_{2} \\ \vdots \\ z_{k} \end{array}\right) $$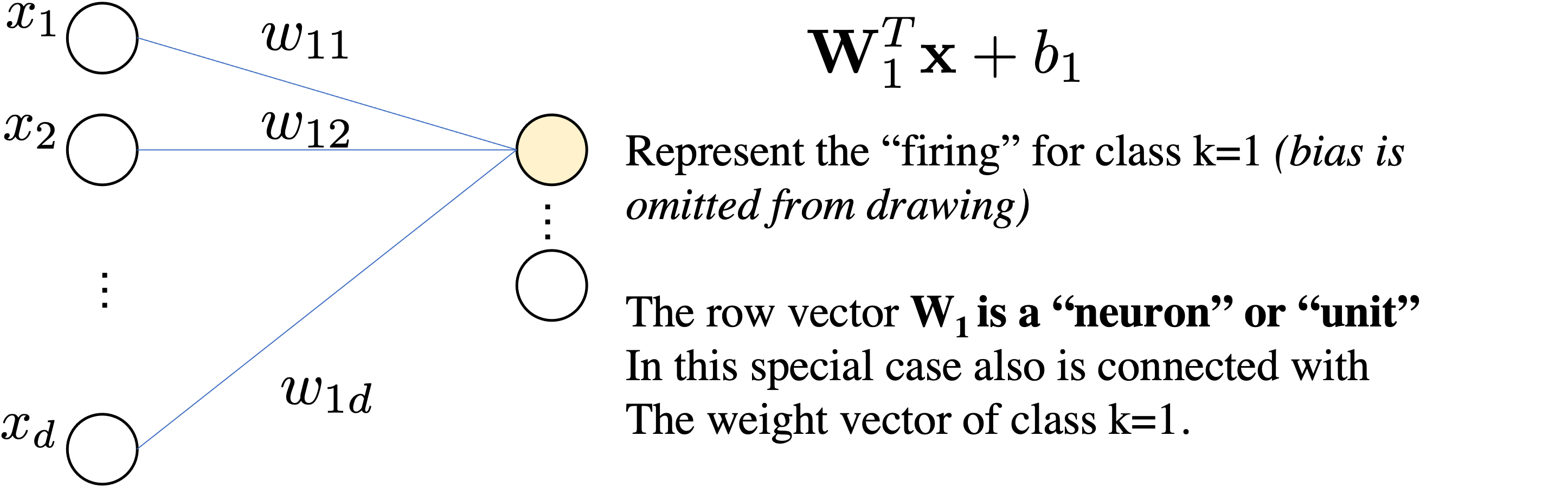
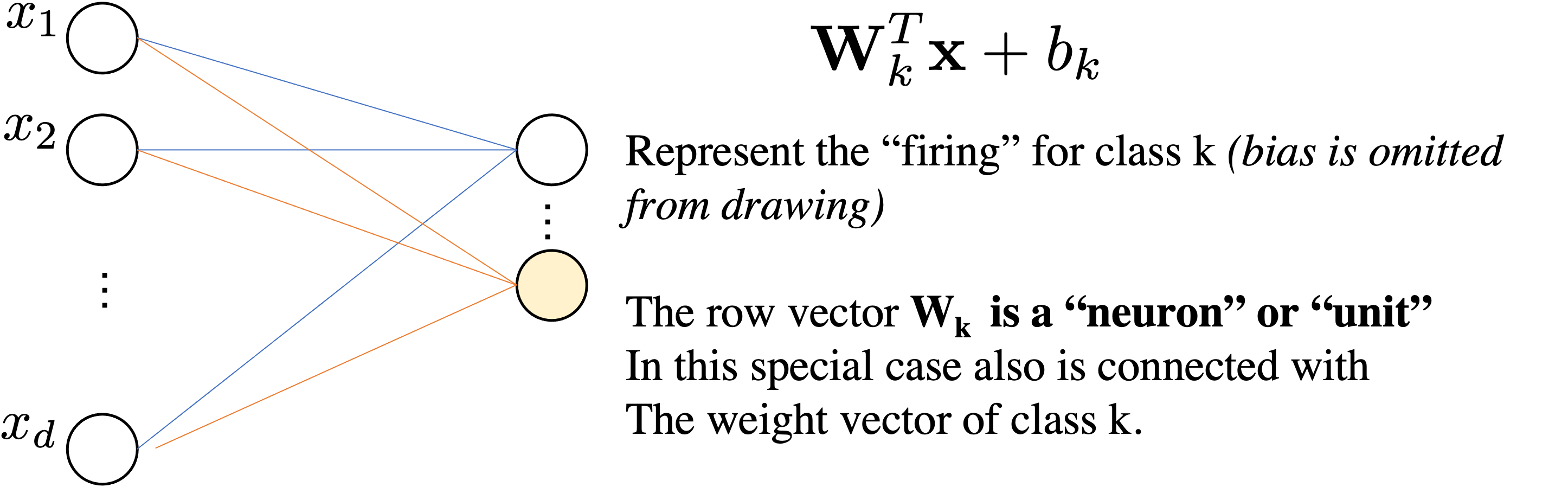


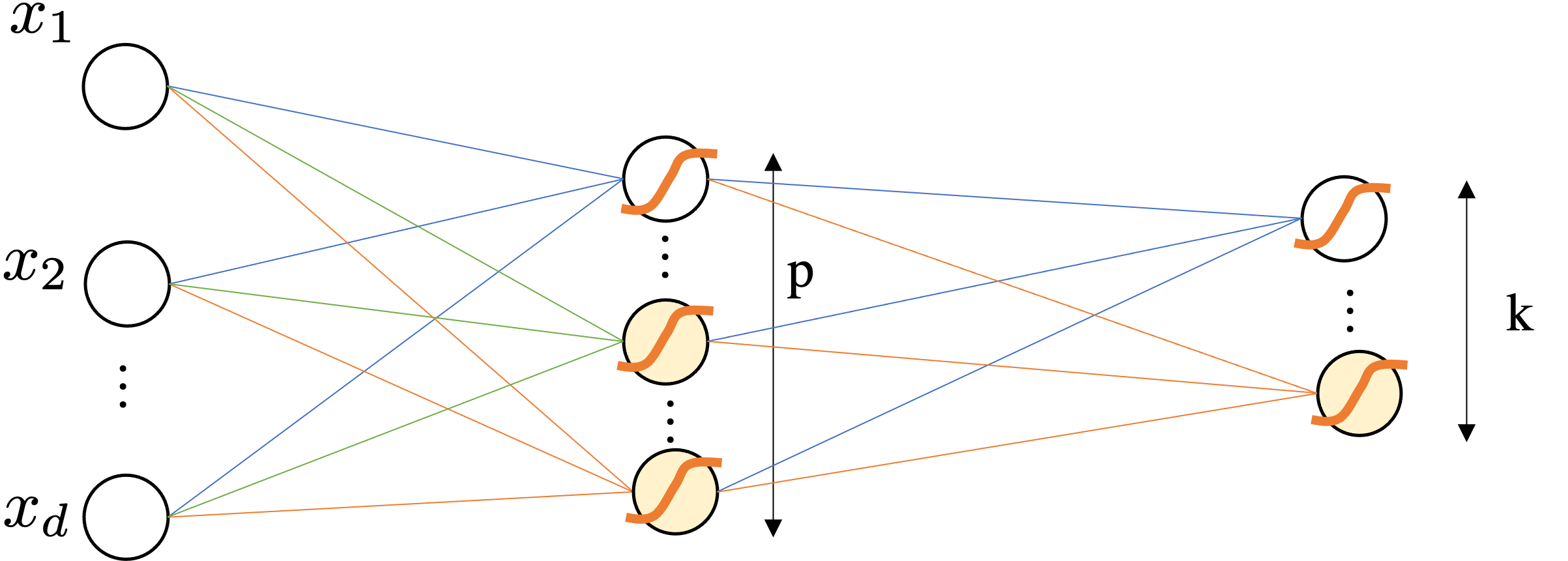
Because it maps the original attribute in $d$ from an dimensionality $p$ and then $p$ is used for classifying.
A priori you do not know what $\mathbf{W}^1$ may learn.
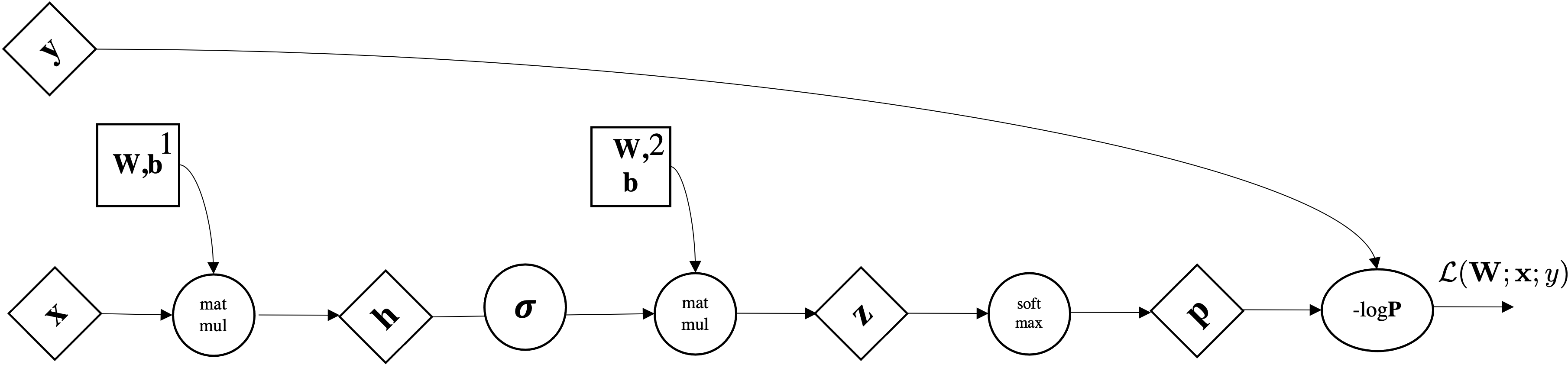
$$\mbf{p}=\sigma(\mathbf{W}^2\underbrace{\left(\sigma(\mathbf{W}^1 \mathbf{x} + \bmf{b}^1) \right)}_{\bmf{\phi}(x)} + \bmf{b}^2)$$$$\text{dim. analysis:} \quad d \mapsto p \mapsto k$$Very important: Activation Functions are computed element-wise.
$$ \sigma(z)= \max(0,z) \quad \text{ReLu}$$

Assume $\mathbf{W}$ is your matrix and $w=\mathbf{W}_{ij}$ is a scalar inside your matrix.
L(w)For i,j=1....dims:
L(w+eps)[L(w+eps)-L(w)]/eps at position ij, so store it in $\nabla_{\mbf{W}}\mathcal{L}_{ij}$At the end you have your numerical gradients $\nabla_{\mbf{W}}\mathcal{L}_{ij}$.
$\forall l \in [1\ldots,L]$:
$\forall l \in [1\ldots,L]$:

Returning to functions of a single variable, suppose that $y = f(g(x))$ and that the underlying functions $y=f(u)$ and $u=g(x)$ are both differentiable. The chain rule states that
$$\frac{dy}{dx} = \frac{dy}{du} \frac{du}{dx}.$$What is the derivative of loss wrt x in the equation below? $$y = loss\big(g(h(i(x)))\big)$$

This is what we wanted: $$\frac{\partial\mathcal{L}}{\partial x},\frac{\partial\mathcal{L}}{\partial y},\frac{\partial\mathcal{L}}{\partial z}$$
Forward pass

What is the value of the gradient of $\mathcal{L}$ on $y$?: $$\frac{\partial\mathcal{L}}{\partial y} = \frac{\partial\mathcal{L}}{\partial q}\frac{\partial q}{\partial y} = z\cdot 1= -4$$
This is what we wanted: $$\frac{\partial\mathcal{L}}{\partial x},\frac{\partial\mathcal{L}}{\partial y},\frac{\partial\mathcal{L}}{\partial z}$$
Backward pass

This is what we wanted: $$\frac{\partial\mathcal{L}}{\partial x},\frac{\partial\mathcal{L}}{\partial y},\frac{\partial\mathcal{L}}{\partial z}$$
This is what we have
$$\frac{\partial\mathcal{L}}{\partial q}=z, \frac{\partial\mathcal{L}}{\partial z}=q, \frac{\partial\mathcal{q}}{\partial x}=1, \frac{\partial\mathcal{q}}{\partial y}=1$$
The high school way (as we did until now):
$$\frac{\partial\mathcal{L}(x,y,z)}{\partial x} = (\mbf{x}z+yz)^{\prime}=(\mbf{x}z)^{\prime}+(yz)^{\prime} = z = -4$$$$\frac{\partial\mathcal{L}(x,y,z)}{\partial y} = (xz+\mbf{y}z)^{\prime}=(xz)^{\prime}+(\mbf{y}z)^{\prime} = z = -4$$$$\frac{\partial\mathcal{L}(x,y,z)}{\partial z} = x+y = +3 $$from torch import tensor
def neural_net(x,y,z):
return (x+y)*z
x, y, z = tensor(-2., requires_grad=True), tensor(5.,requires_grad=True), tensor(-4., requires_grad=True)
loss = neural_net(x,y,z) # forward pass
loss.backward() # backward (after this I can check the gradients)
for el in [x,y,z]:
print(el.grad)
tensor(-4.)
tensor(-4.)
tensor(3.)torchviz simplifies the plot)! pip install torchvizfrom torchviz import make_dot
from torch import tensor
def neural_net(x,y,z):
return (x+y)*z
x, y, z = tensor(-2., requires_grad=True), tensor(5.,
requires_grad=True), tensor(-4., requires_grad=True)
loss = neural_net(x, y, z) # forward pass
loss.backward() # backward (ok now I can check the gradients)
for el in [x, y, z]:
print(el.grad)
print(loss)
make_dot(loss, params=dict([('x', x),('y', y),('z', z)]))
tensor(-4.) tensor(-4.) tensor(3.) tensor(-12., grad_fn=<MulBackward0>)
import torch
from torchvision.models import AlexNet
model = AlexNet()
x = torch.randn(1, 3, 227, 227).requires_grad_(True)
y = model(x)
make_dot(y, params=dict(list(model.named_parameters()) + [('x', x)]))
Just remember that you have to do at a generic gate:

Multiply the gradient that you receive with your local gradient

Given the above function, can you perform forward and backward pass by writing all the local values and local gradient, by applying the chain rule?
(Direct computation of the gradient does not count for solving it, though you may be using it to double check)












This is what implements the Sigmoid Layer in Pytorch:

This is what implements the Sigmoid Layer in Pytorch:

This is what implements the Sigmoid Layer in Pytorch:

class ComputationalGraph:
def forward(inputs):
#1. pass inputs to input layers/gate
#2. forward the computational graph
for gate in self.graph.nodes_topologically_sorted():
gate.forward()
return loss # the finale gate outputs the loss
def backward():
for gate in reversed(self.graph.nodes_topologically_sorted()):
gate.backward() # chain rule applied with local grads
return inputs_grads
class MultiplyGate:
def forward(x,y):
self.x = x # save local grads dz/dy
self.y = y # save local grads dz/dx
return x*y # eval function z = x + y
def backward(dz):
dx = self.y * dz # [dz/dx * dL/dz]
dy = self.x * dz # [dz/dy * dL/dz]
return [dx, dy]
$\forall l \in [1\ldots,L]$:
Below we take the partial derivative wrt class j, so it is not in vector notation:
$$\partial_{z_j} \mathcal{L}(\mathbf{y}, \hat{\mathbf{y}}) = \frac{\exp(z_j)}{\sum_{k=1}^q \exp(z_k)} - y_j = \mathrm{softmax}(\mathbf{z})_j - y_j$$It is a GLM!
Below we take the partial derivative wrt class j, so it is not in vector notation:
$$\partial_{z_j} \mathcal{L}(\mathbf{y}, \hat{\mathbf{y}}) = \frac{\exp(z_j)}{\sum_{k=1}^q \exp(z_k)} - y_j = \mathrm{softmax}(\mathbf{z})_j - y_j$$p = [0.2 0.7 0.1] y =[0 1 0]
dL/dz = [0.2 (0.7-1) 0.1] = [0.2 -0.3 0.1]
$\forall l \in [1\ldots,L]$:








Matrix notation (I dropped the layer number but $\mbf{W}$ is $\mbf{W}^{[1]}$): $$ \mbf{h} = \mbf{W}\mbf{x}+\mbf{b}$$
Vector Notation (slice a single row) let's consider the i-th row of $\mbf{h}$ so $h=\mbf{h}_i$:
$$ h = \mbf{w}^T\mbf{x}+b \quad \text{where } \mbf{w} \text{ selects i-th row of } \mbf{W}$$





$\forall l \in [1\ldots,L]$:
AI & ML are interesting with striking applications but price to pay...